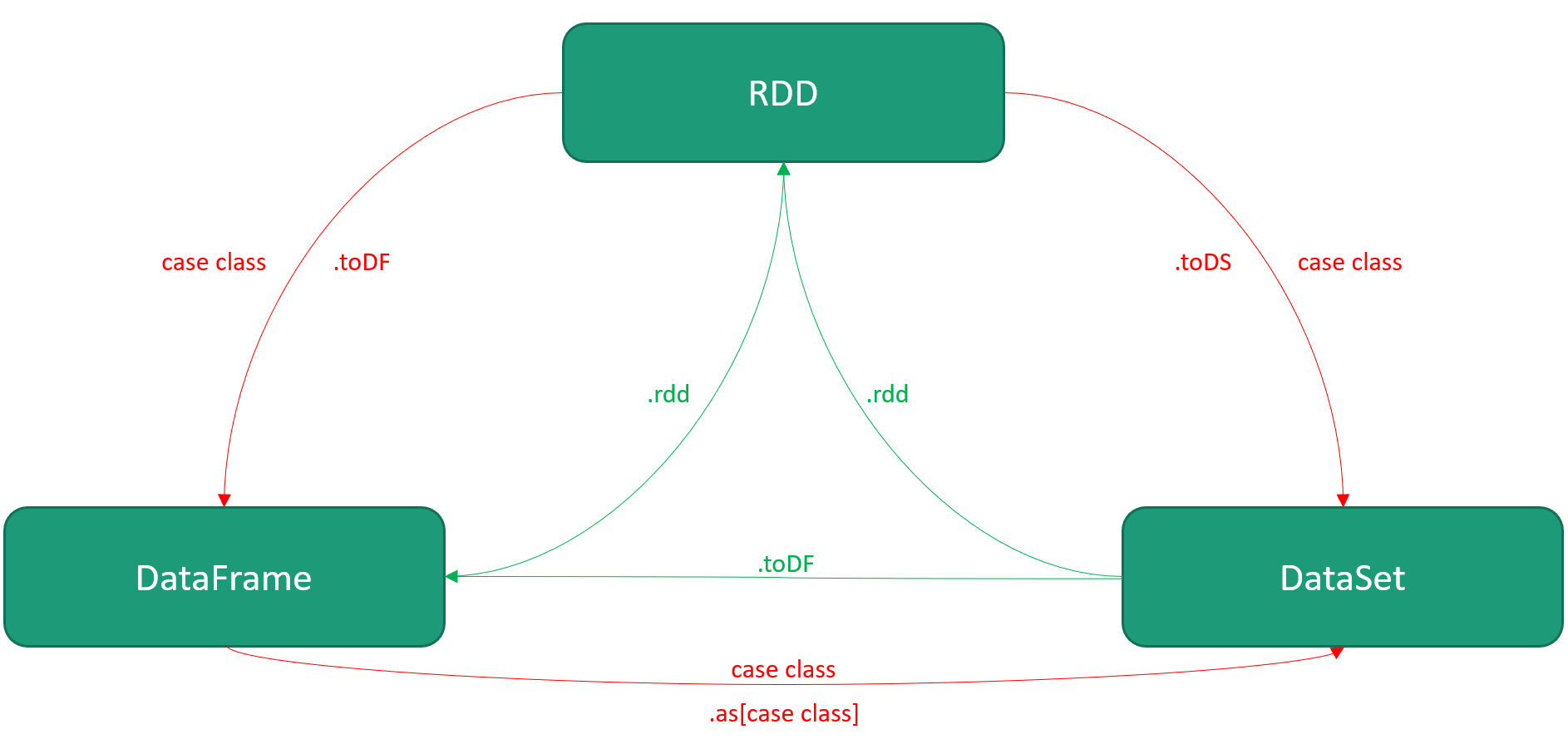
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> val structType: StructType = StructType(StructField("name", StringType) :: StructField("age", IntegerType) :: Nil)
structType: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(age,IntegerType,true))
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> val data = peopleRDD.map{ x => val para = x.split(",");Row(para(0),para(1).trim.toInt)}
data: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[41] at map at <console>:33
scala> val dataFrame = spark.createDataFrame(data, structType)
dataFrame: org.apache.spark.sql.DataFrame = [name: string, age: int]
|