一道有意思的SQL
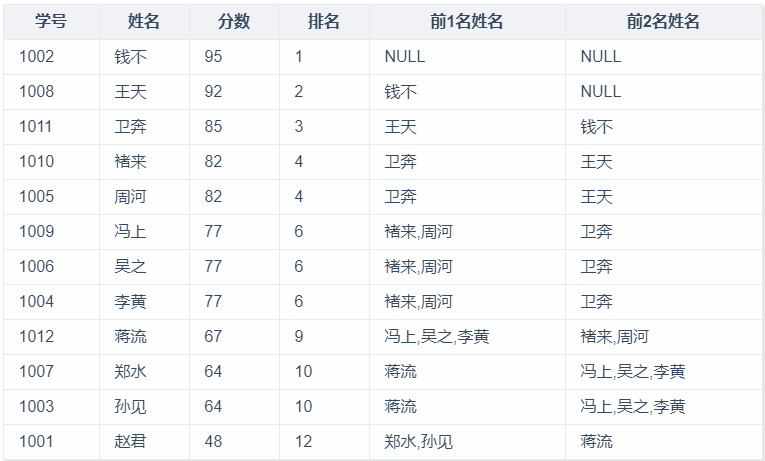
今天题发现一个有趣的题目:找到一个班级里成绩排名,并算出每个人的前1名和前2名作为超越的对手,如果没有前1名,则找前2名和前3名。例如:有两个第八名,则没有第九名,第十名的前一名是第八名,第十名的前2名是第七名
举个例子:
一个班级的某科目成绩单如下:
| 学号 | 姓名 | 分数 |
|---|---|---|
| 1001 | 赵君 | 48 |
| 1002 | 钱不 | 95 |
| 1003 | 孙见 | 64 |
| 1004 | 李黄 | 77 |
| 1005 | 周河 | 82 |
| 1006 | 吴之 | 77 |
| 1007 | 郑水 | 64 |
| 1008 | 王天 | 92 |
| 1009 | 冯上 | 77 |
| 1010 | 褚来 | 82 |
| 1011 | 卫奔 | 85 |
| 1012 | 蒋流 | 67 |
需要获取到每个人的排名以及他所在前1名同学和前2名同学的姓名,目标结果如下所示。
拿到题目首先造数据:
1 | DROP TABLE IF EXISTS SCORE; |
首先给每位同学成绩进行排名,分为跳跃排名和不跳跃排名。实际业务中,前1名和前2名是自己下次考试的超越对手。其中跳跃排名是正常使用的排名,而不跳跃排名是为了进行关联而使用的关联条件。
1 | SELECT |
执行结果如下:
| id | name | sc | rk | rk2 |
|---|---|---|---|---|
| 1002 | 钱不 | 95 | 1 | 1 |
| 1008 | 王天 | 92 | 2 | 2 |
| 1011 | 卫奔 | 85 | 3 | 3 |
| 1010 | 褚来 | 82 | 4 | 4 |
| 1005 | 周河 | 82 | 4 | 4 |
| 1009 | 冯上 | 77 | 6 | 5 |
| 1006 | 吴之 | 77 | 6 | 5 |
| 1004 | 李黄 | 77 | 6 | 5 |
| 1012 | 蒋流 | 67 | 9 | 6 |
| 1007 | 郑水 | 64 | 10 | 7 |
| 1003 | 孙见 | 64 | 10 | 7 |
| 1001 | 赵君 | 48 | 12 | 8 |
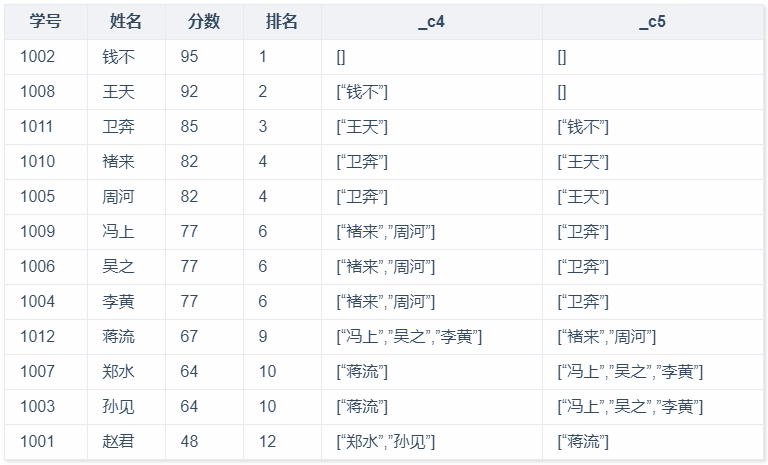
然后进行两次自关联,分别找到每一位同学的前1名和前2名,由于存在排名并列的情况,join后势必存在数据膨胀,也就是说前1名可能是多位同学,这里使用collect_list函数对结果进行收敛。
1 | WITH tt AS( |
执行结果如下:

不难看出最后三位同学{郑水,孙见,赵君}的数据是有问题的,前1、2名数据有重复,为什么呢?
经过测试,实际上单独找前1名或者前2名使用collect_list都没有重复,如果找前1名和前2名放在一起会产生重复,因为collect相当于省略了group by操作,对膨胀的数据进行聚合(列转行),在第一次join中已经出现了数据膨胀,第二次join会加剧数据膨胀,而collect_list是在所有join完成之后,对重复的数据仅进行一次收敛。所以使用collect_set才会符合预期要求。
代码如下:
1 | WITH tt AS( |
执行结果: